Fantastic Google Summer of Code Experiences and How I Found them
Posted on Thu 26 August 2021 in posts • 8 min read

Figure 1: Photo by Rhi Photography on Unsplash
Fantastic Google Summer of Code Experiences and How I Found them
For the last three months, I had the opportunity to join the Google Summer of Code in its 2021 version as a Deep Learning intern at the Machine Learning for Science (ML4SCI) organization. My project was part of the End-to-End (E2E) group and dealt with applying Deep Learning for boosted top quark mass regression for the CMS experiment at CERN. To commemorate the end of this opportunity full of learning, I decided to write an article describing my experience as a GSoC summer student, so buckle up and let's get started!
0. A Preliminary: What is GSoC?
Google Summer of Code or GSoC (as commonly referred to among avid software development students) is a ten weeks program organized by Google designed to bring students from all around the world to work with open source organizations. Every year, students apply to work on an open-source project over the summer with organizations from various backgrounds, from web development, software engineering, machine learning, to life sciences, and more!
1. Start Early in the Process
The GSoC program is notorious for being quite competitive. Every year, thousands of students apply to the program and submit their proposals to open-source organizations. To make the process easier, GSoC organizers put a great effort into setting the timeline for the whole program. For example, the timeline for GSoC 2021 is as follows:


Figure 2: GSOC 2021 Timeline (source: Google Summer of Code)
Yet don't let the ample time given for every step deceive you! One mistake I noticed many students fall into every year (myself included) is to leave the proposal submission step to the last minute. But since many organizations have different procedures for applying before submitting the proposals, many students will fail to finish their proposals on time and move to the next step of the application process. So the hot take is to start early! Give yourself enough time to research the organizations, understand their selection process, and eventually write that strong proposal!
2. Wait, what is ML4SCI anyway?
My main goal in GSoC was to join machine learning projects that try to solve real-world scientific problems. One of the organizations leading such projects is the Machine Learning for Science organization (ML4SCI). It is an umbrella organization that applies machine learning to projects in science. It brings together researchers from universities and scientific laboratories with motivated students to contribute to cutting-edge science projects across many disciplines.
ML4SCI currently includes projects from a variety of fields. Some projects for instance explores the uses of machine learning for particle reconstruction and classification in high-energy physics at CERN, deep learning-based searches for dark matter in astrophysics, applications of machine learning techniques to data returned from planetary science missions, applications of quantum machine learning to science, and others.
Its goals are to grow the open-source community in machine learning for science by addressing important scientific challenges and transferring the knowledge and tools of machine learning across the disciplines.
3. ML4SCI Application Procedure

Figure3: Image by Bram Naus (source: Unsplash)
Out of the many exciting projects offered by the ML4SCI organization, I decided to apply to the mass regression using machine learning proposed by the End-to-End group at ML4SCI (more on the project next).
The first step of the application procedure of the ML4SCI is an evaluation test that helps you showcase your machine learning and Data Analysis skills. My evaluation test contains three Deep Learning exercises, successfully training and tuning a Deep Learning model using Tensorflow and Pytorch. Each time I faced difficulties during this period, I found the ML4SCI community on Gitter a great place to ask for help and exchange ideas with other applicants and mentors about the proposal.
4. Oh, the Proposal! Is it that Difficult to Prepare?
After completing the evaluation task, you should be proud of yourself! It is no easy feat! Now, it is time to start preparing your proposal. As I have previously stated, take your time and invest in writing the proposal. Trust me, with enough time you can craft a well-researched and strong proposal. There are many methods to write a proposal, and I found the GSoC guide provided here to be quite clear and comprehensive. Make sure to go through it in detail, and whenever in doubt, don't hesitate to visit the community on Gitter and contact the mentors for further questions. Once you are confident of your proposal, take a deep breath and hit that submit button.
5. I am IN!

Figure 4: GSOC Acceptance
Congratulations! You are finally admitted to the GSoC program, and swag aside, you are invited to the ML4SCI community meetings! Depending on your project, you should expect weekly meetings with your group where you will have the opportunity to share your progress and receive valuable feedback from your mentors and colleagues. In the meantime, you might want to contact your mentor to discuss your next steps and the changes needed in your proposal.
6. Cool, but what about your Project?
It is about time that you might be wondering what about my project! Buckle up as you are about to take a sweet ride in the world of Machine Learning and Particle Physics!
a. (Physics) Story Time
The detection of top quarks is an important task in the CMS experiment at CERN (European Organization for Nuclear Research). Top quarks are expected to be produced by many physical experiments and studied in depth at the CMS physics program at CERN. For example, quantum mechanics allows the Higgs Boson particles to fluctuate for a very short time into a top quark and a top anti-quark, which promptly annihilate each other into a photon pair. Therefore, the study of top quarks and their measurements is important to the study of the Higgs Boson among other tasks.
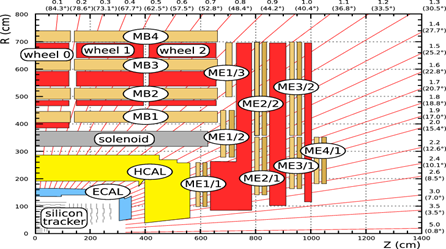
Figure 5: Schematic view of a CMS quadrant (Source: CERN Document Server)
Before going into more details about the used architecture, let's take a step back and study our data a bit. What are collisions? As previously mentioned, the CMS Experiment produces a large amount of data on elemental particles, and that is through colliding particles and evaluating the results generated. As many particles are produced with every collision, they are pushed away with momentum and angle of their own and hit the different detector layers of the CMS. Then those "hits" are recorded and used in many projects at CERN.
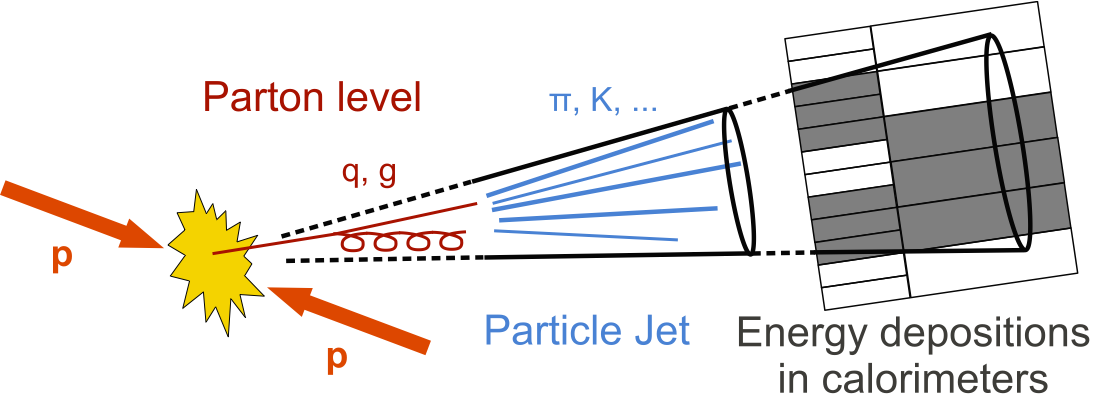
Figure 6: Spray of Particle 'Jets' in time of Particle collisions (source: CERN)
As you can see, those hits stacked layer by layer can be studied as pictures. Hence the use of specialized deep learning models such as Convolutional Neural Networks whose strength comes in handy when dealing with image-like structures.
b. The Machine Learning Side
Hence comes my project: to use Deep Learning for the regression of the top quark mass using data gathered from particle collisions at the CMS Experiment. I have trained a class of Convolutional Neural Networks, called ResNets or Residual Neural Networks, to predict the mass of boosted top quarks.
Now that we got the physics part covered, we can move to the juicy part. Residual Neural Networks or ResNets for brevity, are a class of convolutional neural networks used over the years as the backbone of many computer vision networks. Resnets have been used for exceptionally deep models and been able to win the ImageNet challenge back in 2015.
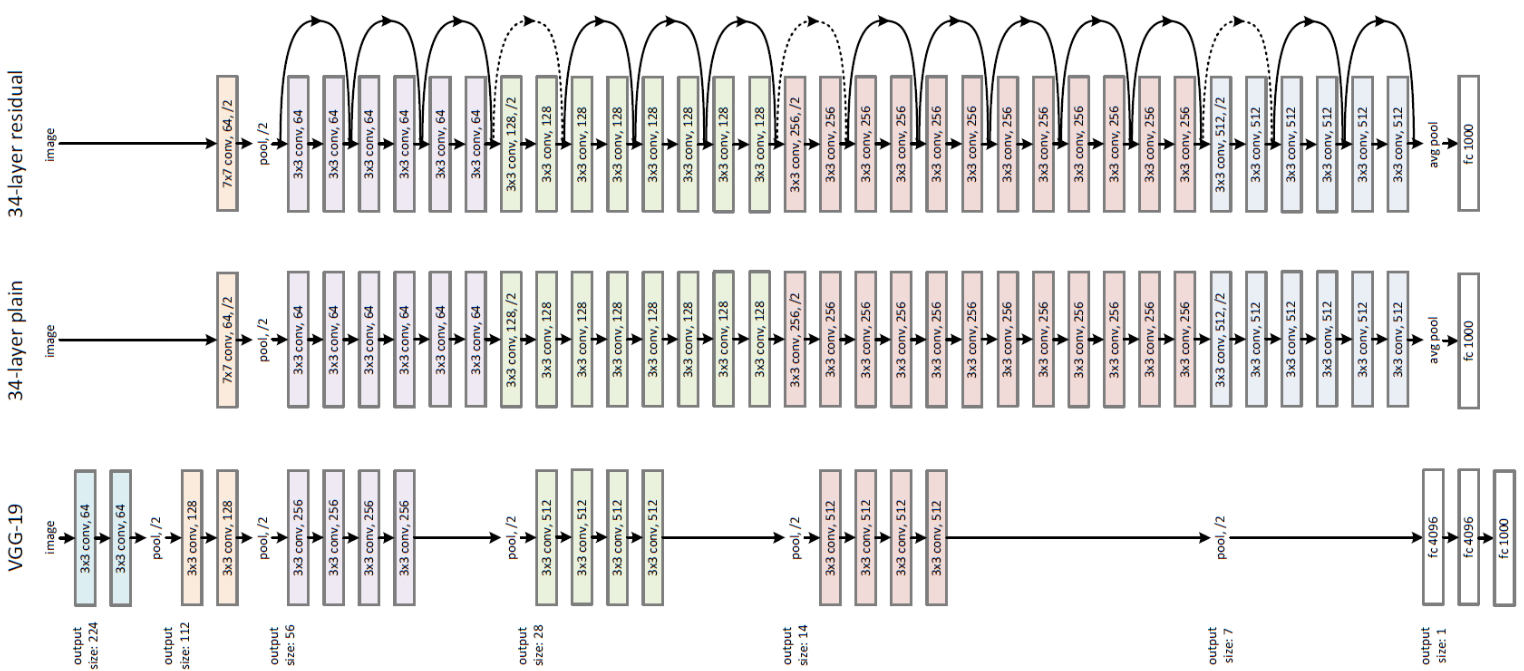
Figure 7: 34-layer ResNet with Skip / Shortcut Connection (Top), 34-layer Plain Network (Middle), 19-layer VGG-19 (Bottom) (source: Towards Data Science)
Why ResNets, you ask? In our experimental setting, the data we are using as previously mentioned have similar structures to images. Thanks to ResNets' ability of increasing their depth without performance drop, they offer a powerful ability to learn complex patterns and the flexibility to improve models' performance as we increase their depth.
c. Training Experiment
For training the model, we have used data generated using Pythia simulation software. We had over 2 million samples divided over training, validation, and test sets with a 90-5-5 split.
For preprocessing, we rescaled the pixel values of each jet layer to values between 0 and 1. We also converted all values below 1e-5 to zero and high outlier values to 1. We used these strategies to accelerate training and reduce the noise introduced by outliers in training.
For the target variable, we performed an unbiasing process where we transformed the mass distribution into a uniform distribution and divided the values by the maximum mass value (500 GeV). Using this technique, we reduce the risk of model bias over one mass subgroup and mitigate overfitting.

Figure 8: Distribution of target mass after unibiasing and rescalling
After preprocessing the data, we train a ResNet-15 model for 25 epochs. As for our loss function, we used the Mean Absolute Error (MAE) for both training and evaluation.
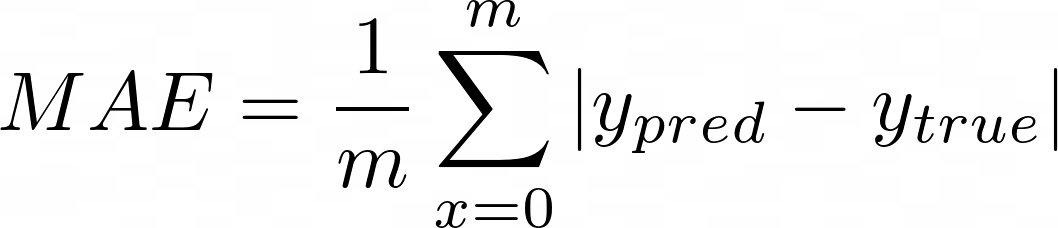
Figure 9: MAE Formula
We also employed the Mean Relative Error (MRE) as an evaluation metric to benchmark the model performance and compare it with other experiments.
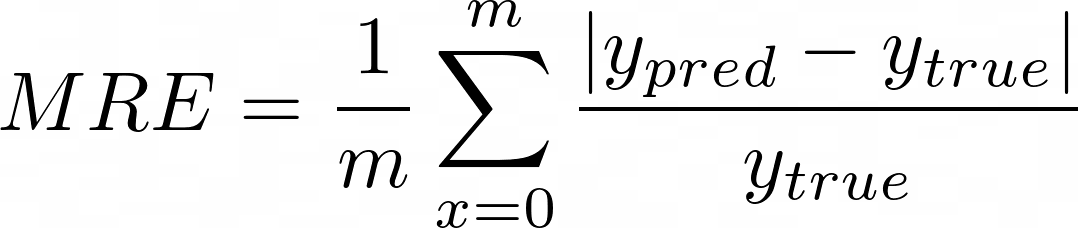
Figure 10: MRE Formula
We used the Adam optimizer and a learning rate scheduler that reduces the learning rate whenever the validation loss no longer decreases to improve model convergence.
d. Results
After training for 25 epochs, the MAE reached 56.43 GeV on the test set. The MRE also reached a percentage of 24.04% on the test set. Not bad, but there is room for improvement!
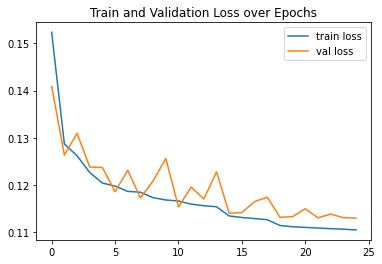
Figure 11: Plot of scaled loss for train and validation sets over time
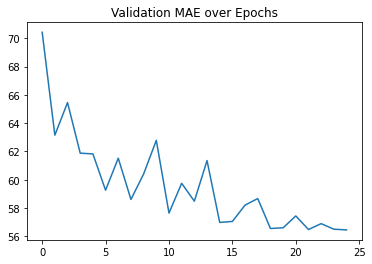
Figure 12: Plot of the Evolution of the validation MAE over training epochs
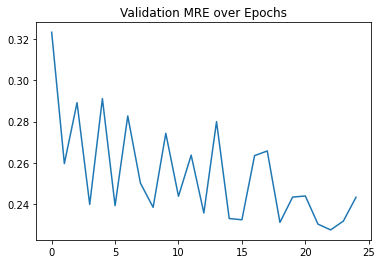
Figure 13: Plot of the Evolution of the validation MRE over training epochs
These graphs prove the model's ability to predict the mass values within reasonable error without overfitting the training set.
To improve the results, we plan to repeat the experiment by adding the extra two layers dubbed dZ and pt to the hits images. Earlier works in top quark classification have shown that the addition of these two layers improved classifier's performance.
7. Don't Forget to Document your Progress!
Now that you have finished your project and passed your final evaluation, Congratulations! You have officially completed your (Fantastic) GSoC experience! One last piece of advice is to make sure that your precious progress and valuable contributions to your project are saved and well documented for future additions. Depending on your organization, you might want to commit your well-commented code to your repository on Github, Gitlab and submit a pull request to your organization's repository.
Final Thoughts
With that, I conclude this fantastic GSoC experience! Over the last three months, I had the opportunity to learn a lot about applying Machine Learning in accelerator physics and meet a motivating community full of brilliant and supportive colleagues and mentors. Despite GSoC wrapping up, I am excited to continue to be part of the E2E group at ML4SCI to improve the top quark mass regression project and facilitate its integration into the CMS detector pipeline. Finally, my thanks go to Google Summer of Code for creating such valuable opportunities and my mentors Davide Di Croce, Sergei Gleyzer, and Darya Dyachkova for their continuous support.
You can learn more about my project here.