Context
Last September represented a milestone in my academic career, as I published my very first academic paper to a machine learning conference! After 2 years of hard work and endless support from my co-authors Zena Kamel and Reem Mahmoud, we managed to publish the Handwriting Identification of Manuscripts and Calligraphy in Arabic (HICMA) dataset to ArabicNLP 2023, colocated with EMNLP 2023, the leading conference in the Arabic langauge processing. HICMA dataset is as the first publicly available dataset that included real-world and diverse samples of Arabic handwritten text in manuscripts and calligraphy.
You can find the paper here, and the dataset along its benchmarking tool can be found as well on the official dataset website hicma.net.
Note: The HICMA dataset is liscenced under Creative Commons Attribution-NonCommercial 4.0 International License. Make sure to consult the rules and regulations before using the dataset in your project.
Dataset
The HICMA dataset contains more than 5,000 images across five different styles and each image is labeled with text and style for the corresponding image. It is the first step towards a more inclusive Optical Character Recognition (OCR) engine capable of detecting texts across underrepresented languages like Arabic. The HICMA dataset is combined from three data sources:
- Source 1: The Free Islamic Calligraphy website sharing Islamic calligraphy paintings in a variety of styles.
- Source 2: The Ibn Bawab Qur’an from the Chester Beatty Library, Dublin, Ireland, written in the Naskh style by Ibn al-Bawwab in the 11th century.
- Source 3: A private collection of manuscripts and religious writings in Naskh style dating back to the 17th century.
Figure 1- Examples of Images from the HICMA dataset (Top-Set1, Middle-Set 2, Bottom- Set3) Figure 2- Word Cloud of Most Occurring Words in the Text Corpus



Aims
Before starting with any modeling task of the dataset, it is essential to perform an exploratory data analysis to get a better understanding of the text corpus’ structure and properties.
In this project, we are especially interested in answering the following questions:
- How does the word distribution differ across the three sources?
- Do the three sources share any common semantic topics?
- What are the most used words in the three sources, and how do these words relate to the topics in each source?
- How do the words cluster in the dataset, and is it possible to relate this clustering to the semantic relationships between the words?
- How do the word relationships differ across the three sources? Is there any common pattern that can be also observed in the complete dataset?
- Are there any outliers that might need to be removed or preprocessed from the dataset before any modeling step?
All the R code used in this project is publicly available on my Github.
Exploratory Data Analysis
First, we extracted and annotated the labels in the dataset based on their position in the sentence using a Part-of-Speech (POS) classification model trained over Arabic text. Using the annotated labels, we next removed numbers,punctuation and common stop words from the dataset.
Next, we calculated and plotted the top terms in the full corpus, Set 1, Set 2 and Set 3 in Figure 3. The figure showcases the top 10 nouns, verbs and adjectives in each set. Figure 3 - Top Terms in the full corpus and the three subsets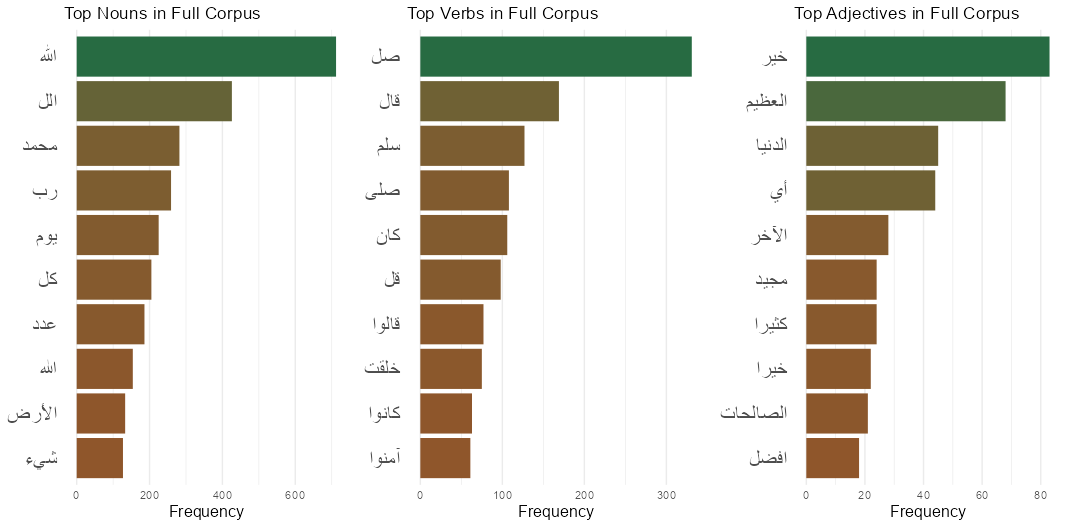
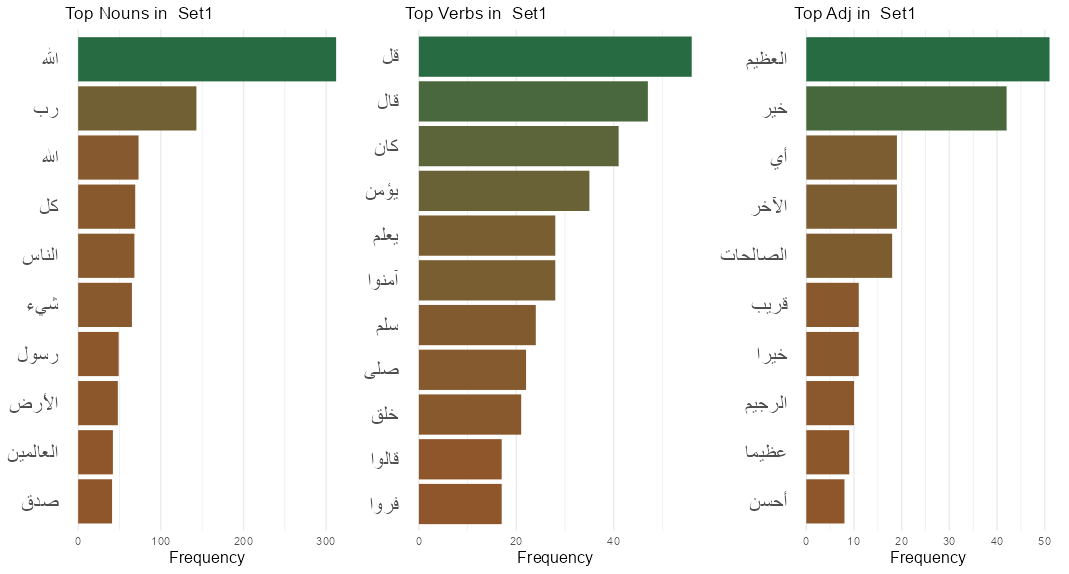
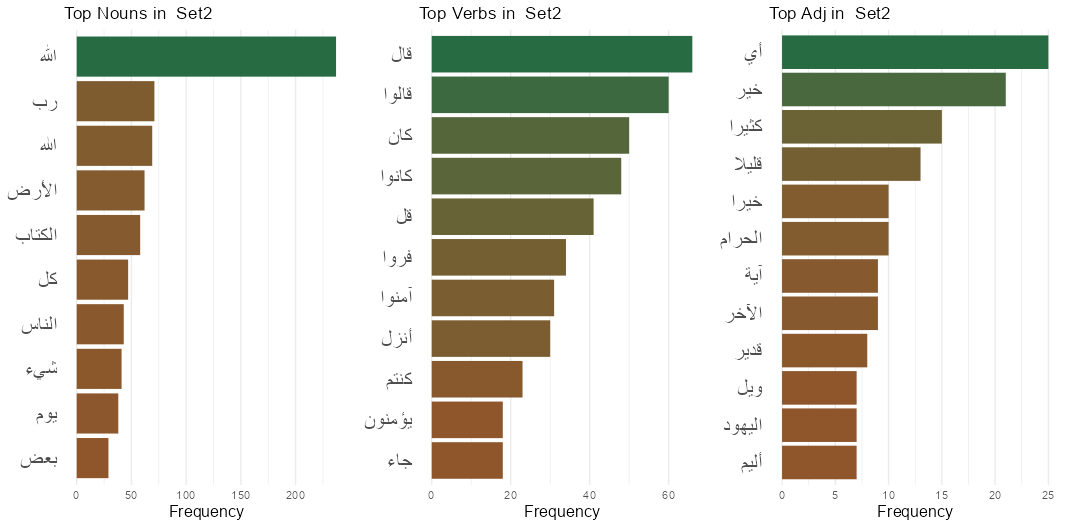
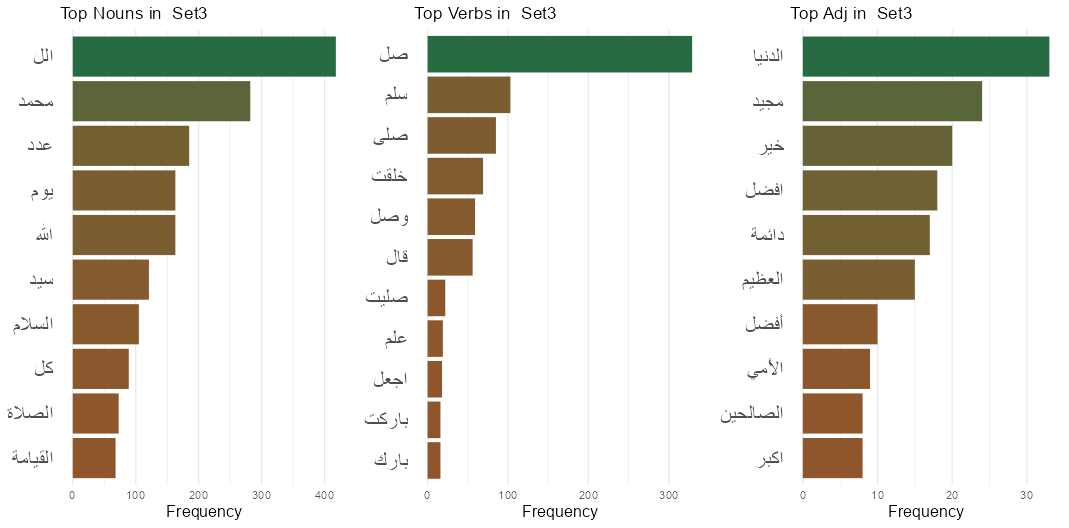
The frequently used words in all three sets include “الله” and “محمد,” which respectively refer to Allah (God) and Muhammad (the last prophet in Islam), along with adjectives and nouns describing the divinity of Allah and praising the prophet Mohamad. Verbs in Set 1 and 2 were mostly related to the verb “قال” (say) in diverse forms (singular, plural, imperative) providing insights into the narration tradition in Islam where text usually mentioned by the prophet is narrated by multiple narrators and is then written down to preserve the chain of narration. The majority of the verbs in Set 3 are in the imperative form, a form usually used in Arabic during prayers and invocations.
Frequency Analysis
We then generated the term frequencies to count the number of occurrences of all words per set. We plotted the distribution of the word frequencies in Figure 4 where x-axis represent the percentage of these words in each sets and the y-axis for counts of the number of words with a specific abundance in the set. Figure 4 - Distribution of words based on their abundance in each set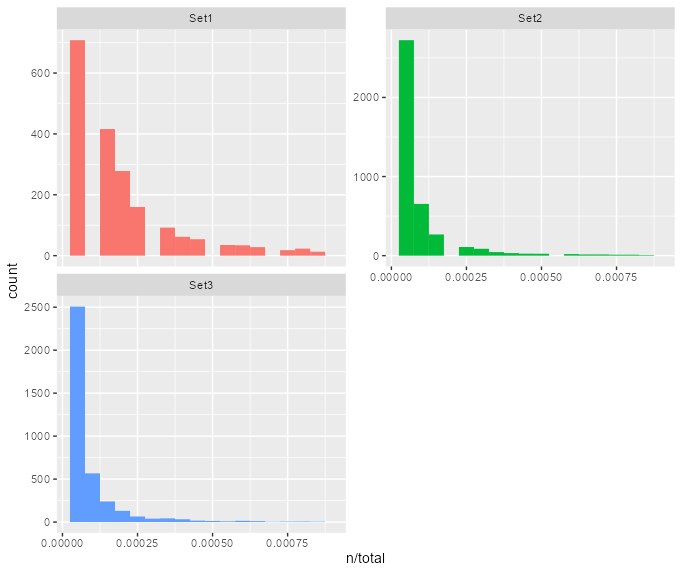
Next, we plotted the frequency analysis of Set 1 vs Set 2 and Set 1 vs Set 3 in Figure 5. Words that are close to the line in these plots have similar frequencies in both sets of texts, Words that are far from the line are words that are found more in one set of texts than another. We notice that the words in the Set1-Set2 panel are closer to the zero-slope line than in the Set 1-Set 3 panel. We also notice that the words are more densely packed in lower frequencies for the Set 1-Set 2 panel compared to the Set 1- Set 3 panel at low frequency. Figure 5 - Frequency Plots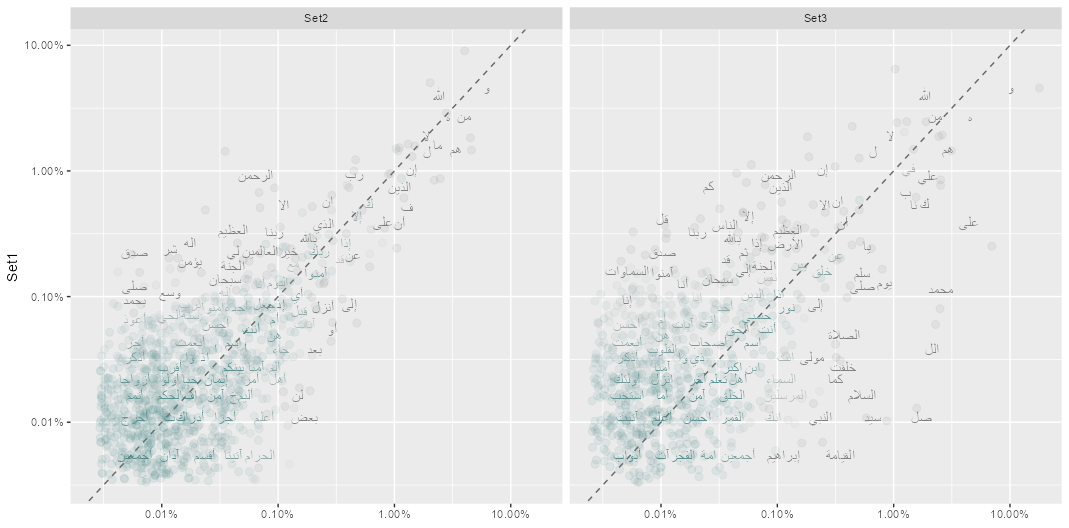
We also calculated the correlation test results for both Set1-Set2 and Set1-Set3 (table 1). The correlation test for Set 1 and Set 2 is higher than the correlation test results for Set 1 and Set 3, agreeing with the results shown in Figure 5.
| Test | Correlation test Set 1/Set 2 | Correlation test Set 1/Set 3 |
|---|---|---|
| t-value | 70.449 | 30.161 |
| degree of freedom | 935 | 671 |
| p-value | <2.2e-16 | <2.2e-16 |
| 95% confidence interval | [0.9065, 0.9269] | [0.7246, 0.78896] |
| correlation estimate | 0.9173 | 0.7586 |
We also plot The Zipf’s law in Figure 6, where each of the three sets are plotted in distinct color. A power law regression line is also fitted to the data and plotted. A result close to the classic version of Zipf’s law can be observed in the plotted lines. The deviations observed at high rank are common since a corpus of text often contains fewer rare words than predicted by a single power law. The deviations at low rank are more unusual, as it seems all three sets uses a lower percentage of the most frequently used words than many languages do. Figure 6 - Zipf law plots for all three sets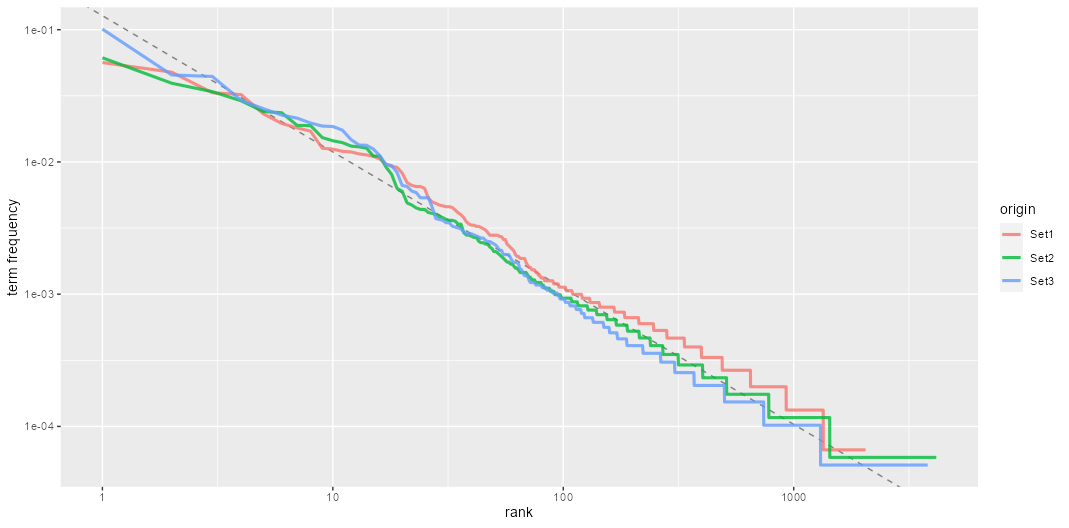
To comprehend the similarities among the three datasets, it is crucial to delve into their origins. One dataset is sourced from a calligraphy paintings website (Set 1), while another originates from the Ibn Bawab Quran (Set 2). Despite the disparate origins of Set 1 and Set 2, it is noteworthy to acknowledge the Islamic tradition of employing Qur’anic text in calligraphy for decorative and blessing purposes, adhering to the prohibition of iconographies in Islam. Given this context, it should not be surprising to find potential thematic and linguistic overlap between these two sets, as they both draw from the same foundational text, the Holy Quran.
In contrast, Set 3 is derived from a private collection of 16th-century Sufi manuscripts utilized in prayer, invoking Allah for protection, blessings, and well-being. This distinction in purpose and context likely contributes to the observable differences in structure and themes when comparing Set 1 and Set 2 with Set 3. The analysis is fortified by the Pearson correlation, where the correlation between Set 1 and Set 2 surpasses that between Set 1 and Set 3 (0.9173 vs. 0.7586).
N-gram Analysis
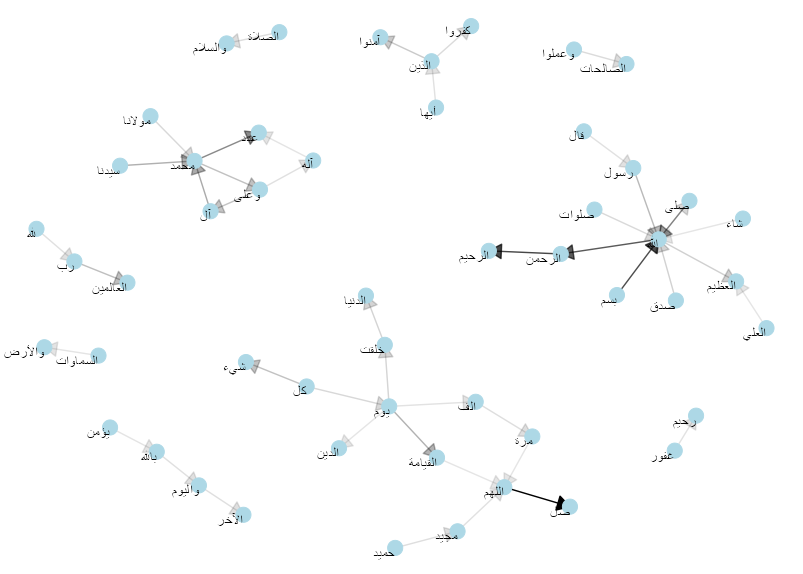
The top words and bigrams are shown in Figures 7 and 8. The terms were ranked based on their tf-idf score in their corresponding set and the top 15 terms (words/bigrams) were extracted and visualized. Figure 7 - Top words based on tf-idf Figure 8 - Top bigrams based on tf-idf Figure 9 - Graph of correlated word pairs for Full Dataset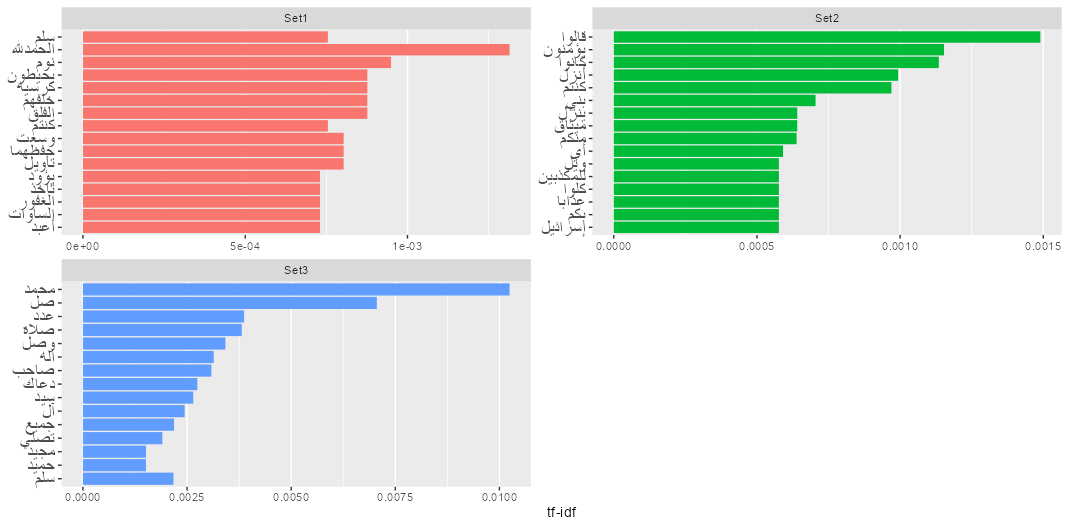
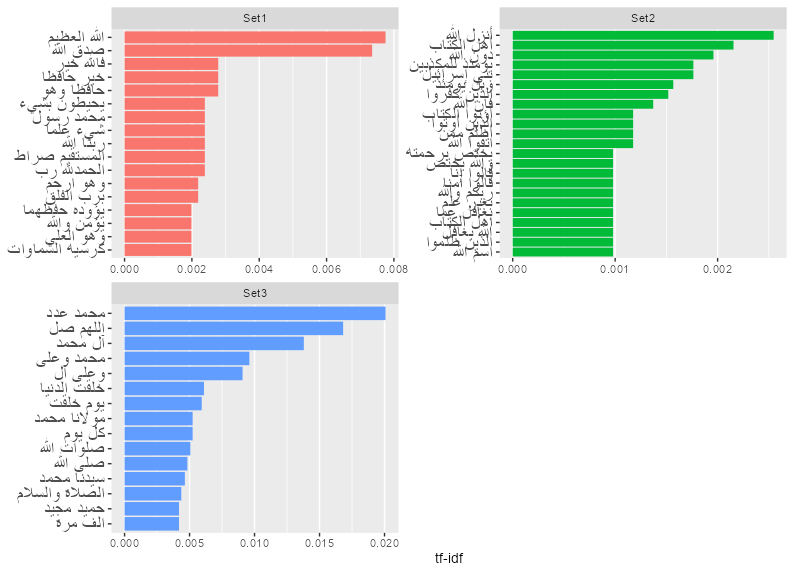
While frequently used words like الله and محمد were no longer shown as the top words in Set 1 and 2 (Figure 7 and 8), the top words shown in both Set 1 and Set 2 are now more diversified and more descriptive of themes recurrent in these sets like importance of faith, praising of Allah, and warning of straying from the righteous path. The imperative tone of Set 3 however stay recurrent in both figures but also involve words for praising Allah and the prophet, also common in invocations and prayers.
To investigate the relationship between the most important words used in the dataset, we plot pairs of words with correlation larger than 0.2 (Figure 9) forming communities in the graph mostly related to Qur’anic verses like “الحمد لله رب العالمين” (Praise be to Allah, Lord of the Worlds), invocations regularly used by Muslim in their daily practices like “بسم الله الرحمن الرحيم”( In the Name of God, the Compassionate, the Merciful), and combination of adjectives commonly used when praising God like “انت ارحم الراحمين” (you are the Most Merciful of the Merciful) or the prophet.
Topic Modeling
After running the LDA model using 10 topics, we generated the top 10 words for every topic and plotted them in Figure 10. We also plotted the gamma probabilities for every sentence, which are the per-sentence-per-topic probabilities for all three sets shown in Figure 11. Figure 10 - Top Terms per Topic Figure 11 - Topic Distribution across Sets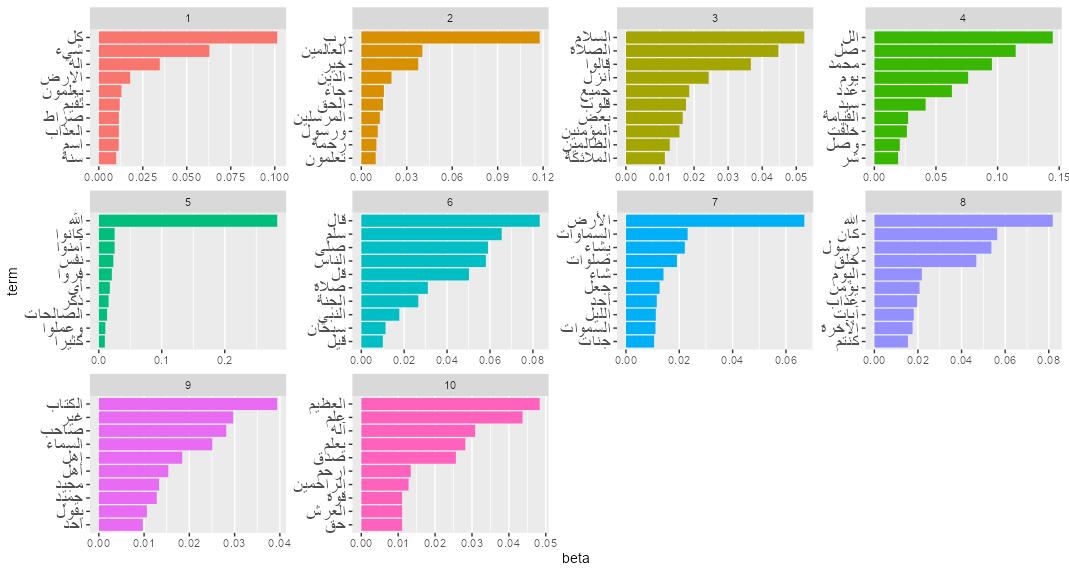
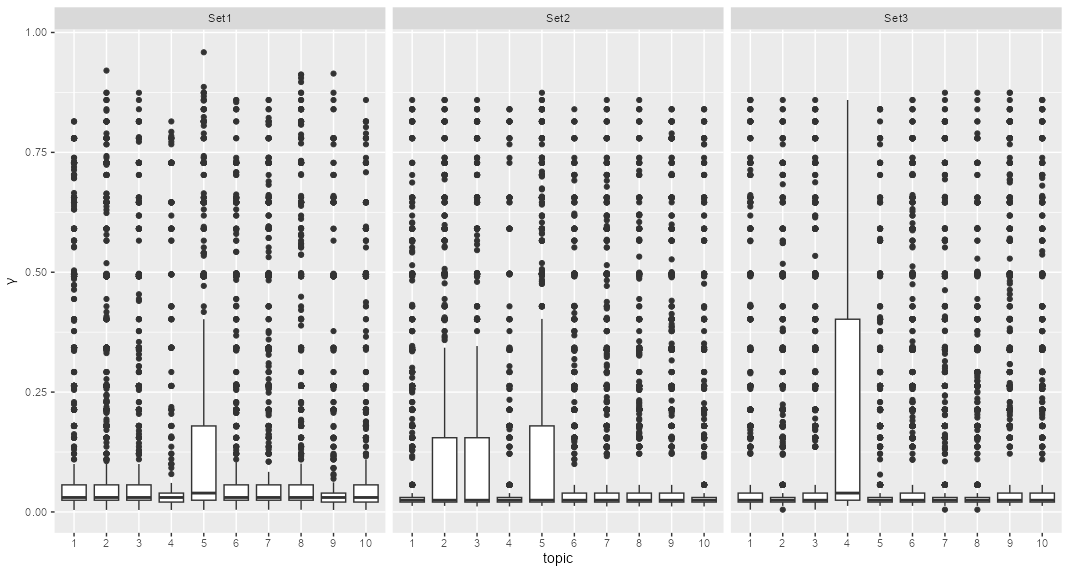
The topic modeling results of Figure 10 show that among the topics with the least outlier for every set, Set 1 and Set 2 share topic 5 as Set 1 has two topics more 2 and 3, while Set 3 has topic 4 with the least outliers. A peak into the top words in topic 5 are related to believing in the message of Allah and doing the virtuous deeds and being reminded of praying. This thematic convergence is not only a recurring motif in the Quran but is also particularly significant in calligraphy paintings. These artworks, beyond serving as decorative elements, serve as constant reminders of the vital role of righteous conduct in the life of a Muslim. Topic 4 mostly tied to Set 3 seems to be related to a specific mantra usually used in invocations “اللهم صل علی سیدنا محمد” (O God, bless Muhammad).
PCA and Clustering Analysis
The sentences were visualized using the first and second principal components, and the sentences were labeled based on their set as shown in Figure 12. Figure 12 - Sentences Distribution in PC1 and PC2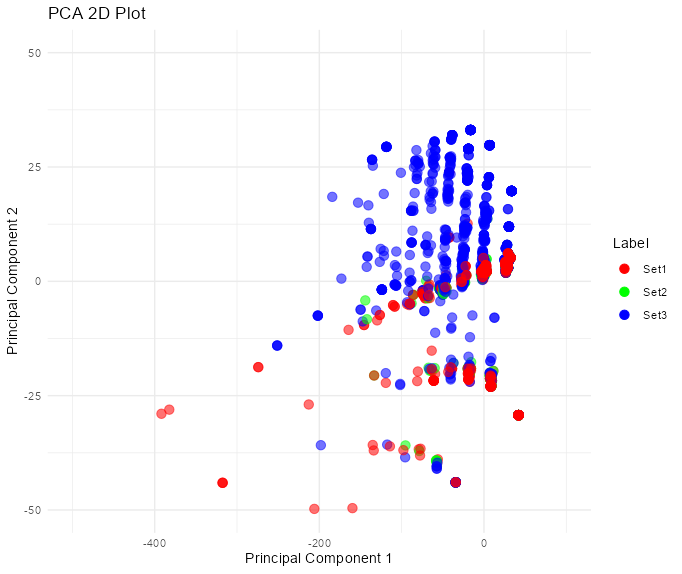
The resulting clustering of the words is also shown in a dendrogram in Figure 13. Figure 13 - Dendrogram of hierarchical clustering of words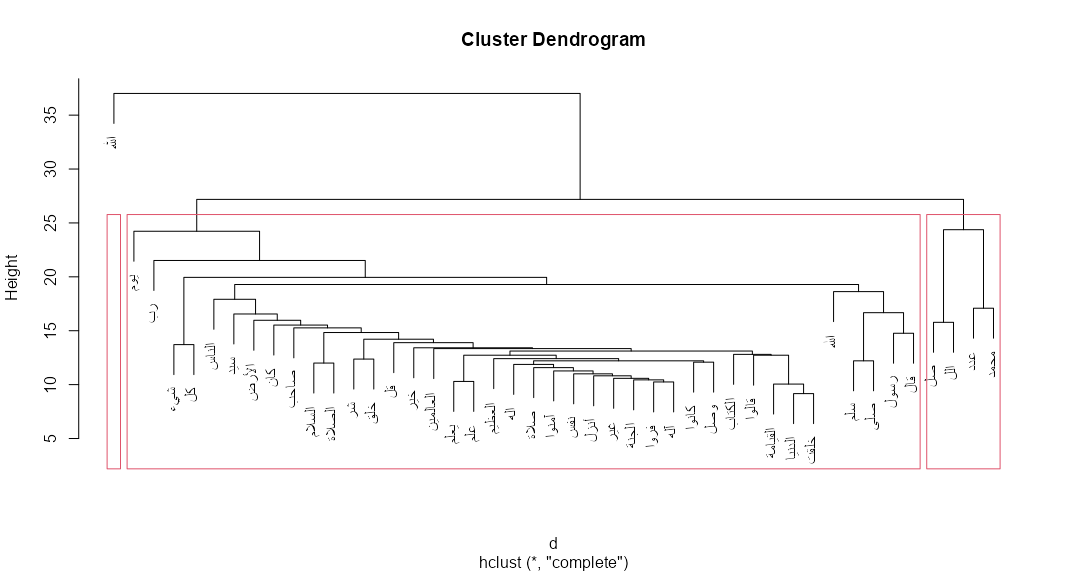
Limitations and Future Works
- Variability in Arabic Words: Arabic words can take different forms based on their part of speech and can be attached to multiple pronouns, resulting in multiple variants with the same meaning. While lemmatization is a possible solution, caution is needed, as using the lemma of a word might lead to the loss of meaningful information regarding tenses and context.
- Typos and Diacritics: Some typos in the added diacritics to the labeling were detected, leading to different formats of the same word. Correction of these typos should be a priority in the next iteration of the project to ensure accurate and consistent labeling.
- Sparsity of Document-Term Matrix: The document-term matrix had a high sparsity in the combined dataset, reaching 99%. While removing very rare and extremely common words helped reduce sparsity, it also resulted in the loss of valuable information present in many word features. The high sparsity limits the effectiveness of the analysis and insights derived from the data.
- Improving Document Encoding Techniques: To address sparsity, we can apply advanced encoding techniques for sentences using pretrained deep learning models. Examples of such models include BERT (Bidirectional Encoder Representations from Transformers) or specialized models like AraBERT for Arabic text. These models can provide more meaningful embeddings and capture relationships between words.
Wrap-up
In this project, we used a combination of visualizations, correlations, principal component analysis, and hierarchical clustering to get a deeper understanding of the HICMA dataset. We analyzed the topics and word relationships in the HICMA dataset as well as detect any outliers. We believe this project will be the first step to develop more accurate and robust models.
All the R code used in this project is publicly available on my Github.
References
- Ismail, A., Kamel, Z., & Mahmoud, R. (2023). HICMA: The handwriting identification for calligraphy and manuscripts in Arabic dataset. Proceedings of ArabicNLP 2023. https://doi.org/10.18653/v1/2023.arabicnlp-1.3
- Schweinberger, M. (n.d.). Pos-tagging and syntactic parsing with R. https://ladal.edu.au/tagging.html#POS-Tagging_non-English_texts
- Silge, J., & Robinson, D. (2017). Text mining with R: A tidy approach. O’Reilly Media