
Ten months ago, I started my work as an undergraduate researcher. What I can clearly say is that it is true that working on a research project is hard, but working on an Reinforcement Learning (RL) research project is even harder!
What made it challenging to work on such a project was the lack of proper online resources for structuring such type of projects;
- Structuring a Web Development project? Check!
- Structuring a Mobile Development project? Check!
- Structuring a Machine Learning project? Check!
- Structuring a Reinforcement Learning project? Not really!
To better guide future novice researchers, beginner machine learning engineers, and amateur software developers to start their RL projects, I pulled up this non-comprehensive step-by-step guide for structuring an RL project which will be divided as follows:
- Start the Journey: Frame your Problem as an RL Problem
- Choose your Weapons: All the Tools You Need to Build a Working RL Environment
- Face the Beast: Pick your RL (or Deep RL) Algorithm
- Tame the Beast: Test the Performance of the Algorithm
- Set it Free: Prepare your Project for Deployment/Publishing
In this post, we will discuss the first part of this series:
Start the Journey: Frame your Problem as an RL Problem

This step is the most crucial in the whole project. First, we need to make sure whether Reinforcement Learning can be actually used to solve your problem or not.
Framing the Problem as a Markov Decision Process (MDP)
For a problem to be framed as an RL problem, it must be first modeled as a Markov Decision Process (MDP).
A Markov Decision Process (MDP) is a representation of the sequence of actions of an agent in an environment and their consequences on not only the immediate rewards but also future states and rewards.
An example of a MDP is the following, where S0, S1, S2 are the states, a0 and a1 are the actions, and the orange arrows are the rewards. Figure 2: example of an MDP (source: Wikipedia)
The new state depends only on the preceding state and action, and is independent of all previous states and actions.
Identifying your Goal

Figure 3: Photo by Paul Alnet on Unsplash
What distinguishes Reinforcement Learning from other types of Learning such as Supervised Learning is the presence of exploration and exploitation and the tradeoff between them.
While Supervised Learning agents learn by comparing their predictions with existing labels and updating their strategies afterward, RL agents learn by interacting with an environment, trying different actions, and receiving different reward values while aiming to maximize the cumulative expected reward at the end.
Therefore, it becomes crucial to identify the reason that pushed us to use RL:
- Is the task an optimization problem?
- Is there any metric that we want the RL agent to learn to maximize (or minimize)?
If your answer is yes, then RL might be a good fit for the problem!
Framing the Environment
Now that we are convinced that the RL is a good fit for our problem, it is important to define the main components of the RL environment:
The states, the observation space, the action space, the reward signal, and the terminal state.
The states: As previously mentioned, any state as in any MDP must satisfy the Markov Property.
Formally speaking, an agent lies in a specific state s1 at a specific time. For the agent to move to another state s2, it must perform a specific action a0 for example. We can confidently say that the state s1 encapsulates all the current conditions of the environment at that time.
- The observation space: In practice, the state and observation are used interchangeably. However, we must be careful because there is a discernable difference between them. The observation represents all the information that the agent can capture from the environment at a specific state.
Let us take the very famous RL example of the CartPole environment, where the agent has to learn to balance a pole on a cart.
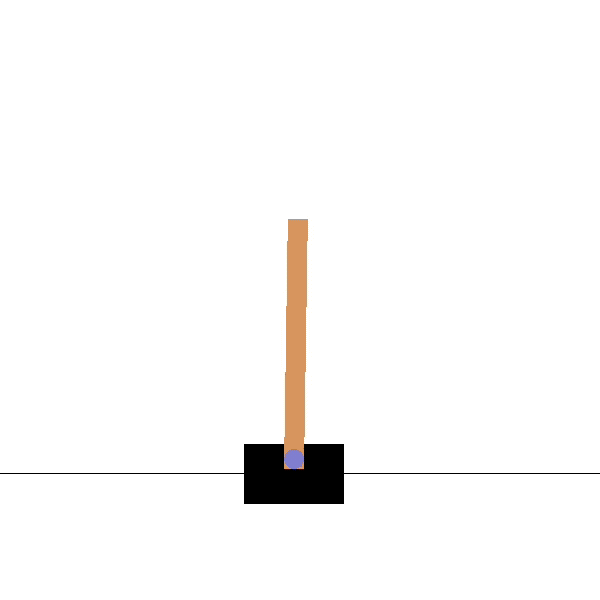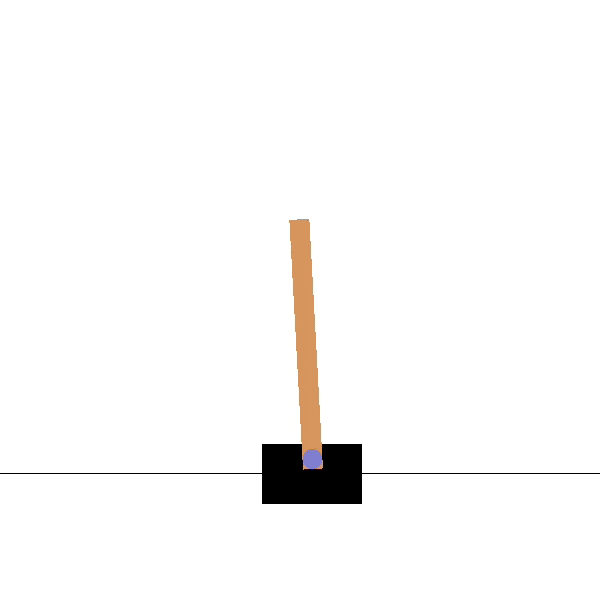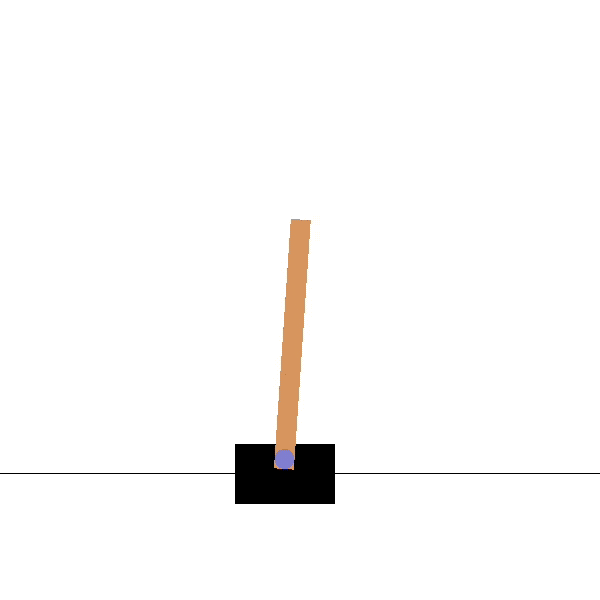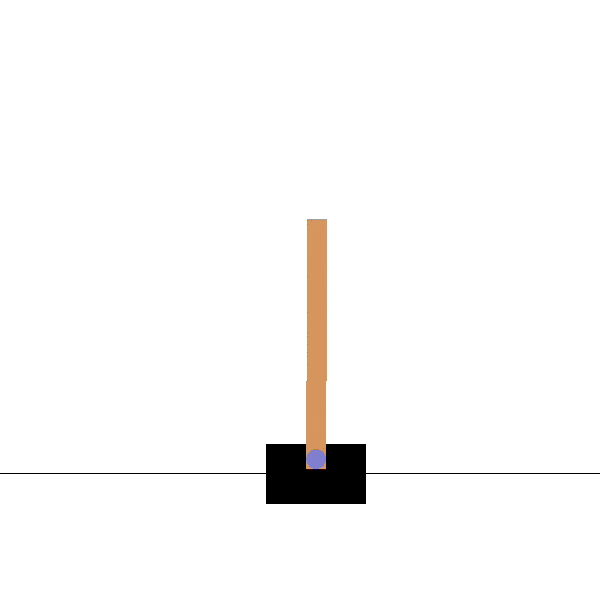
Figure 4: CartPole trained agent in action (Source)
The observations that are recorded at each step are the following:
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | Cart Position | -2.4 | 2.4 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | ~ -41.8° | ~ 41.8° |
| 3 | Pole Velocity At Tip | -Inf | Inf |
Table 1: Observation space for CartPole-v0 (source: OpenAI Gym Wiki)
Another good example might be the case of an agent trying to discover its way through a maze, where at each step, the agent might receive for example an observation of the maze architecture and its current position. Figure 5: Another similar environment is Packman (source: Wikipedia)
The action space: The action space defines the possible actions the agent can choose to take at a specific state. It is by optimizing its choice of actions, that the agent can optimize its behavior.
Let’s get back to the CartPole environment example; the agent in this environment has the choice of taking either of these actions:
Num Action 0 Push cart to the left 1 Push cart to the right Table 2: Action space for CartPole-v0 (source: OpenAI Gym Wiki)
In the Maze example, an agent roaming the environment would have the choice of moving up, down, left, or right to move to another state.
The reward signal: Probably one of the most important components, the reward is the feedback that the agent receives after performing an action to be able to optimize its behavior.
Generally speaking, the RL agent tries to maximize the cumulative reward over time. With that in mind, we can design the reward function in the best way to be able to maximize or minimize specific metrics that we choose.
For the CartPole environment example, the reward function was designed as follows:
“Reward is 1 for every step taken, including the termination step. The threshold is 475.”
Knowing that when the pole slips off the cart the simulation is ended, the agent has to learn eventually to balance the pole on the cart as much as possible, by maximizing the sum of individual rewards it gets at each step.
In the case of the Maze environment, our goal might be to let the agent find its way from the source to destination in the least number of steps possible. To do so, we can design the reward function to give the RL agent a negative reward at each step to teach it eventually to take the least number of steps while approaching the destination.
The terminal state: Another crucial component is the terminal state. Although it might not seem like a major issue, failing to set the flag that signals the end of a simulation correctly can badly affect the performance of an RL agent.
The done flag, as referred to in many RL environment implementations, can be set whenever the simulation reaches its end or when a maximum number of steps is reached.
Setting a maximum number of steps will prevent the agent from taking an infinite number of steps to maximize its rewards as much as possible.
It is important to note that designing the environment is one of the hardest parts of RL. It requires lots of tough design decisions and many remakes. Unless the problem is that straightforward, you will most likely have to experiment with many environment definitions until you land on the definition that yields the best results.
My advice: Try to look up previous implementations of similar environments to get some inspiration for building yours.
Are Rewards Delayed?
Another important consideration is to check whether our goal is to maximize the immediate reward or the cumulative reward. It is crucial to have this distinction set clearly before starting the implementation since RL algorithms optimize the cumulative reward at the end of the simulation and not the immediate reward.
Consequently, the RL agent might opt for an action that might lead to a low immediate reward to be able to get higher rewards, later on, maximizing the cumulative reward over time. In case you are interested in maximizing the immediate reward, you might better use other techniques such as Bandits and Greedy approaches.
Be Aware of the Consequences
Similar to other types of Machine Learning, Reinforcement Learning (and especially Deep Reinforcement Learning) is very computationally expensive. So you have to expect to run many training episodes, testing and tuning iteratively the hyperparameters.
Moreover, some Deep RL algorithms (like DQN) are unstable and may require more training episodes to converge than you think. Therefore, I would suggest allocating a decent amount of time for optimizing and perfecting the implementation before letting the RL agent train enough.
Conclusion
In this article, we laid the foundations needed to make sure whether Reinforcement Learning is a good paradigm to tackle your problem, and how to properly design the RL environment.
With that, we reach the end of the first part of this series!
In the next part: “Choose your Weapons: all the Tools you Need to Build a Working RL Environment”, I am going to discuss how to build the infrastructure needed to build an RL environment with all the tools you might need!
Buckle up and stay tuned!
